Figure 1: Topical map of user requirements in CST

Final report
1995-09-06
for approval by:
CEN, CENELEC, ETSI and EWOS
Editor: fiorvarur K·ri ”lafsson
This report was developed by a Project team that was set up under mandate M/037 from EC to develop a European strategy for Character Set Technology (CST) standardization. The work is a direct continuation of the CST workshop that was held in Luxemburg 1-2 December 1994 [1].
The final report is submitted to CENELEC, ETSI, EWOS and CEN for approval. CEN/TC304 is responsible for its final approval.
B. Bibliography
E. General recommendations of the CST-workshop
F. The indigenous languages of Europe
G. Extract from the Nordic report on cultural requirements
The work of other organizations then started to affect the future of CST standardization in Europe:
This development led to the disbanding of IT/WG-CSC and the establishment of CEN/TC304 in late 1992. The new committee has an extended scope, derived from a first draft taxonomy that was based on the Nordic report on cultural requirements.
In December 1993, the EC Senior Official Group on IT standardization (SOGITS) through its secretariat in EC DG.III, issued a standardization mandate in the field of CST, asking CEN/TC304 to develop a European strategy for CST standardization.
In order to execute this mandate, TC304 organized a workshop and established the Project Team PT01. The workshop was on European User Requirements for Internationalization of IT and Character Set Technology and took place in Luxemburg 1-2 December 1994. The Project Team is basing its work on the results of this workshop [1], see further Part I and Annex E.
The ultimate goal of this work is that new CST standards meet user requirements and provide basis for a true multilingual infrastructure in Europe. A further goal is that users know which standards are available and may obtain guidance on their usage.
The report defines a European policy and strategy with respect to CST, aligns the
existing and ongoing standardization activities with this policy, and finally it
defines a European work program for CST, including a taxonomy and European sub-repertoires of ISO/IEC 10646. This work is based on a clear definition of European user requirements. All required standardization activities in order to realise the user functionality should be defined.
See also Annex C.
The project team has met the requirements of the mandate (see Annex C). A joint European work programme for standardization in the field of CST has been agreed between CEN, CENELEC, ETSI and EWOS (see Part IV). This work programme has been based on a clear definition of user requirements (see Part I). These user requirements were gathered at the open workshop held in Luxemburg in December 1994. A taxonomy for CST is presented in Part II. A strategy for implementation of it is identified in Part III which involves not just standardization but also R-and-D, promotion and coordination activities.
This part aims to define which are the requirements for CST standardization in Europe
on part of the prospective users of the standards. The users include other standardizers,
End users, IT applications, IT industry, service providers and public procurers.
For the purposes of this study, user requirements are grouped in an order of priority,
ranging from High through Medium to Low. A high priority means that the topic should
be addressed urgently in order to improve the usability of IT for most people. Medium priority is assigned when the action would improve the usability of IT for some
people, or improve it marginally for most users. Low priority topics would not improve
usability for most users, but general benefits would accrue, or some selected groups
of users would benefit marginally.
Note that this part of the report tries to describe the user requirements regardless
of whether they are to do with standardization or not. The standardization perspective
is introduced in Part III.
Attributes:
those general aspects of a character used independently of design (font or style),
to convey additional abstract meaning, e.g. bold or underline.
Character:
a member of a set of elements used for the organization, control or representation
of data [ISO 4873]. NOTE: Characters are sub-divided into graphic characters and
control characters.
Character set (Character repertoire):
a finite set of different characters that is complete for a given purpose [ISO 2382-4].
Character Set Technology:
the technology for handling characters within IT and providing multi-cultural functionality
in informatic and telematic systems. This includes input, coding, interchange, rendition,
transformation, identification, ordering and other ways of manipulating character data by electronic means.
Charmap:
a text file describing a coded character set. Each character set description file
defines characteristics for a coded character set and the encoding of characters.
Other information about the coded character set may also be in the file. Coded character
set character values are defined using symbolic character names followed by character
encoding values [ISO/IEC 9945-2].
Coded character set, Code:
a set of unambiguous rules that establishes a character set and the one-to-one relationship
between the characters of the set and their bit combinations [ISO 4873].
Coding scheme:
a collection of rules that maps the elements of one set onto the elements of a second
set.
Coding:
the process of allocating unique bit combinations to an individual character according
to established rules.
Combining character:
a member of an identified subset of the coded character set of ISO/IEC 10646 intended
for combination with the preceding non-combining graphic character, or with a sequence
of combining characters preceded by a non-combining character [ISO/IEC 10646].
Control function:
an action that affects the recording, processing, transmission or interpretation
of data, and that has a coded representation consisting of one or more bit combinations
[ISO 6429].
Cultural convention:
a convention of an information system which is functionally common between regional
cultures, but may differ in presentation, operation behaviour or degree of importance.
NOTE: application or organizational cultures are not considered here [3].
Cultural register:
a register of cultural conventions related to IT.
Cultural requirements:
requirements due to properties of the language(s), commonly accepted rules for its
use -- especially in written form -- or other special characteristics of a society
in a certain geographic area [5].
Diacritical mark:
a combining character which forms part of a letter.
Europe:
the geographic area whose boundaries are the Ural Mountains, the Caspian, Black and
Mediterranian Seas, the Atlantic Ridge and the North Pole.
Fallback representation:
an approximate representation of a character, made for equipment not capable of representing
the character correctly.
Font:
a collection of glyph images having the same basic design, e.g. Courier Bold Oblique
[ISO 9541-1].
Glyph:
a recognisable abstract graphic symbol which is independent of any specific design
[ISO 9541-1].
Graphic character:
a character, other than a control function, that has a visual representation, normally
hand-written, printed or displayed, and has a coded representation consisting of
one or more bit combinations [ISO 4873].
Indigenous:
native to a certain geographic area.
Internationalization:
a process of producing an application platform or application which is capable of
being localized for (almost) any cultural environmental easily. NOTE: an internationalized
information system does not have a dependency on any specific culture unless it is localized to that selected culture [3].
Letter:
a graphic character that is in the alphabet of a natural language [5].
Locale:
the definition of the environment of a user that depends on language and cultural
conventions. It is made up from one or more categories. Each category is identified
by its name and controls specific aspects of the behaviour of components of the system
[ISO/IEC 9945-2].
Localization:
a process of adapting an internationalized application to a specific cultural environment
[5].
Operating system:
software that controls the execution of programs and that may provide services such
as resource allocation, scheduling, input/output control and data management [ISO
2382-1].
Ordering:
an operation by which two different objects (for example two character strings) are
assigned a context-free deterministic ordering [3].
Script:
a set of graphic characters used for the written form of one or more languages [3].
Examples: Latin script, Cyrillic script, Greek script.
Special character:
a graphic character that is not a letter, a digit or a spacing character [ISO 2382-4].
Symbol:
a character or letter, or stylized representation of an object.
Taxonomy:
a classification of concepts or a terminology system.
Telematics:
the application of information and communications technologies and services, usually
in direct combination.
Transcription:
the process whereby the pronunciation of a given language is noted by the system
of signs of a conversion language. A transcription system is of necessity based on
the orthographic conventions of the conversion language. Transcription is not strictly
reversible [ISO 3602].
Transformation:
any conversion of coded character data, including transliteration, transcription,
code conversion and fallback rules.
Transliteration:
the process which consists of representing the characters of an alphabetical or syllable
writing by the characters of a conversion alphabet. In principle, this conversion
should be made character by character [ISO 3602]. NOTE: transliteration is a reversible process.
User interface:
the part of a system with which the user interacts [ANSI X3.172].
Users (1. of IT) Persons or organizations utilising IT in their work or leisure (2. of CST-standards) Users of IT , providers of IT-technology, developers of IT-standards.
| 10646 | see UCS |
| ANSI | American National Standards Institute |
| API | Applications Programming Interface |
| ASCII | American Standard Code for Information Interchange (7-bit code covering the English alphabet) |
| ASN.1 | Abstract Syntax Notation no. 1 |
| BLISS | a picture symbol language used by severely motor and speech disabled |
| BMP | Basic Multilingual Plane (Part 1 of ISO/IEC 10646) |
| CADDIA | Co-operation in Automation of Data and Documentation for Imports/Exports and the Management and Financial Control of the Agricultural Market |
| CCITT | see ITU |
| CEN | ComitÈ EuropÈen de Normalisation |
| CENELEC | ComitÈ EuropÈen de Normalisation …lectrotechnique |
| CEPT | Conference EuropÈen des Postes et TÈlecommunications (see also ETSI) |
| CLS | Cambridge Language Survey |
| CSC | Character Sets and Coding |
| CST | Character Set Technology |
| DIS | Draft International Standard |
| EAGLES | Expert Advisory Group on Language Engineering Standards |
| EBCDIC | Extended Binary Coded Decimal Interchange Code |
| EC | The European Commission |
| EDI | Electronic Data Interchange |
| EN | European Standard |
| ENO | European Numbering Office |
| ENS | European Nervous System |
| ENV | European Pre-Standard |
| EPHOS | European Procurement Handbook for Open Systems |
| ETSI | European Telecommunications Standardization Institute |
| EU | The European Union |
| EWOS | European Workshop on Open Systems |
| HTTP | HyperText Transfer Protocol |
| ICT | Information and Communication Technology |
| IDA | Interchange of Data between Administrations |
| IE | Information Engineering |
| IEC | International Electrotechnical Commission |
| IETF | Internet Engineering Task Force |
| IRV | International Reference Version (of ISO/IEC 646) |
| ISO | International Organization for Standardization |
| IT | Information Technology |
| ITSTC | IT Steering Committee (of CEN, CENELEC and ETSI) |
| ITU | International Telecommunications Union |
| ITU-T | The Telecommunications standardization part of ITU |
| JTC1 | Joint Technical Committee no. 1 (of ISO/IEC, covering IT-standardization) |
| LE | Language Engineering (follow-up of LRE) |
| LRE | Linguistics Research and Engineering |
| MIME | Multiple-purpose Internet Mail Extension |
| MLIS | Multilingual Information Society |
| MOTIS | Message Oriented Text Interchange System |
| ODA | Open Document Architecture |
| OSI | Open Systems Interconnection |
| POSIX | Portable Operating Systems Interface |
| PT | Project Team |
| R-and-D | Research and Development |
| SGML | Standardized Generalized Mark-up Language |
| SC | Sub-Committee |
| SOGITS | Senior Officials Group on IT Standardization |
| SQL | Structured Query Language |
| STRÕ | Sta›lar·› Õslands (Icelandic Council for Standardization) |
| TC | Technical Committee |
| TC304 | Technical Committee no. 304 (of CEN, covering Character Set Technology standardization) |
| TEDIS | Trade EDI Systems |
| TERENA | Trans European Research and Education Network (formerly RARE and EARN) |
| TIDE | Telematics for Disabled and Elderly people |
| TG/CS | Technical (Liaison) Group on Character Sets (EWOS, formerly TLG/CS) |
| TR | Technical Report |
| UCS | Universal Multiple-Octet Coded Character Set (ISO/IEC 10646) |
| WG | Working Group |
| X.400 | ITU-T recommendation on MOTIS |
It is convenient to consider a number of large easily identifiable groups of users
and then to examine their needs in relation to applications and tasks they need to
perform.
A rapidly increasing percentage of these working people will make use of IT in some
form or another, whether directly with word processing, or indirectly using data
bases or data processing. Their tasks will all involve reading input and output via
characters. To a large extent these characters will be the ones in their local language,
but at some time or other many of the users will have the need to interact with other
users whose language or culture uses an alternative character set.
To avoid incomprehension, or at least inefficiency, they must be able to access these
"foreign", unfamiliar characters. Additionally, users will interact with IT "tools",
e.g. software which may present feedback and help information in another language.
Neither the tools nor the medium must impose any barrier to users' efficiency. Users'
requirements are for access to own language scripts and fonts and translation from/to
others for interaction with other countries, nationalities and cultures.
Users in the working population are characterized by aptitudes, training and experience
which generally fit the task they perform. That task may demand a high degree of
"task fit", in cultural and language terms. Different and highly specific user requirements may often be identified within user groups or professions, such as authors and
writers (technical and scientific, fiction), journalists, translators and interpreters,
engineers, scientists, medical specialists, etc.
This whole group of users is held within defined age limits, somewhere between 15
and 65, but still includes many people with special needs, particularly in the context
of this study, such as elderly and disabled.
Other people have requirements for interaction with public services utilising IT,
such as information retrieval services, shopping and banking services and even self-service
vending machines for many everyday activities, such as car parking, purchase of tickets and general small items of merchandise. This group is characterized by a very
much wider range of age, possibly from as young as five years, up to 80 or even 90.
A large proportion of this group may have special needs, not just visual and physical
handicaps, but mental handicaps as well, and simply by being very young or very old.
The range of capabilities and aptitudes is large and includes both those with no
education or training, and users with highly specialized training and education and
a wealth of experience.
This leisure group has at least as great a requirement for language and cultural exchange
as working people, if not more so. However, in general their encounters with texts
in other languages are more sporadic and they have less familiarity with IT. Another reason for highlighting this group is the proportion temporarily or permanently
embedded within a culture other than their own, with the requirement, therefore,
to be able to communicate to a culture outside the one in which they dwell.
The significance of visual deficiencies lies especially with those having acuity or
astigmatism problems, who may have a problem perceiving fine detail in character
sets, making it especially difficult to distinguish diacritical marks or the detail
of some non-Latin characters. The general significance relates to form and fonts and character
size, over all of which the user should be able to have some control.
Blind IT users are now beginning to be able to master graphical user interfaces supported
by combined sound and tactile interfaces, after a period with great problems introduced
by new, and for them, inaccessible technology. When introducing new CST these users expect not to be left behind again, but to find their alternative ways of displaying
and controlling information built into the user interfaces from the start. One such
need is the alternative representation of characters in Braille for tactile display.
Physical deficiencies are an issue relevant to this study, because of their impact
on manipulation of IT input devices. There are also more general issues of control
and display devices e.g. text phones, Teletext (Minitel/Viewdata/Videotext), Braille
(including keyboards), touch screens, mice and operating systems, not addressed in this
study, but which falls into the domain of ETSI.
Nationally developed systems are in a critical situation now in the area of internationalization.
One such is text telephony, mainly used for text conversation in the telephone network
by deaf, hard-of-hearing, speech-impaired and deaf-blind people. The users are impatient to get support for an internationally useful replacement of the
currently incompatible national systems.
Teletext is the medium used, for example, for subtitling of TV. It has a general requirement
for the internationalization of character representation, but also for standardising
use of colours and other effects of expressing specific non-language related contents of the TV programme.
Finally, support for sign languages within the context of CST should be developed
to cater for the need from transcribed documentation and education in these languages.
The symbolic languages used by people with language disabilities i.e. Bliss and Pictogram needs support in the international IT environment both for local and remote communication.
Education in pronunciation is highly related to modern IT implementations, and a
support of phonetic transcription is needed in that sector.
An important long-running initiative within the European Union is the so-called TIDE
programme (Telematics for Disabled and Elderly People). Since 1992 TIDE has been
running with the aim to improve the quality of life for disabled and elderly people
and to improve the European industry and market in products and services that meet their
needs.
Past and current TIDE projects and other activities in the area are summarized below:
Braille:
progress on standardization, as Braille alphabets are not all identical, e.g. work
in ISO TC 173, work on contraction systems, text to Braille conversion.
BLISS:
which is a picture symbol language for use by severely motor and speech disabled,
employing a standard Bliss-symbol Graphical Character Set (Reg. no. 169 in the ISO
International Register of Coded Character Sets to be used with Escape Sequences).
Sign language representation:
many deaf people communicate with sign language, which needs coded representation.
TIDE has three projects dealing with signs.
Text telephones:
used by many deaf, hearing impaired, speech impaired and deaf-blind people. Activities
in COST 219 and COST 220, and standardization work in ETSI and ITU.
Teletext:
international exchange of television programs, including Teletext, raises the problem
of conversion and transliteration. A similar problem arises with sub-titling.
Character sets and control codes:
need for definition of minimal subsets of existing standards, e.g. ISO/IEC 10646-1,
ISO 6429. In particular real-time control of conversation is critical.
Symbols for signing and posting: is used, for example as a standardized way of informing which accessibility features for disabled people are available in an application. Work to define more symbols is ongoing in ETSI and ITU.
These needs are specialized and professional, and they originate from users such as
standardizers, political administration, procurers, manufacturers, application developers,
service providers, user organizations and professionals such as librarians and linguists. These people normally also have the role of end users -- using the technology
for their job and leisure -- but has the added role of being responsible for others'
use of the technology too.
The requirements of intermediate users originate from the intrinsics of the technology,
that is how
it works, and not just the results which are the main interest of end users. Many
of the requirements on how it works are essentially the same as end user requirements,
such as functionality, consistency, inter-operability, preciseness, efficiency, security, economic viability.
But some standardization requirements come from the question on how to make it work,
such as guides for making standards in the field, guides for implementation in applications,
standards for APIs to be used by application developers, generic standards on APIs for programming language standards developers, standardized profiles for which
coded character sets to use in communications, registry standards for reference in
other standards, and overall description of all existing and required standardization
efforts with priorities and work allocation provided. Actually almost all of the standards
are written for the use of intermediate users, as end users do not care about for
example how characters are coded or applications are programmed or letters are communicated, as long as it works.
A summary of requirements in the field of CST for different intermediate types of
users is given below. The individual requirements are further elaborated and listed
in clauses 6 and 7.
Standardizers
have major requirements on a diversity of levels. First of all they use each others'
standards, for example the coded character set standards are used in programming
languages, and the programming languages are used to define database languages. For
this use to be consistent for example across programming languages or communication standards
there is a need for guides on the use of CST in such standards. Member bodies have
requirements for their national and cultural specifications to be precisely defined and referencable uniquely, and standards writers have a need to be able to use this
information in a well defined way. Last, but not least, standardizers need to know
how all the standards work together in an appropriate model, so they know what is
available or expected and plan accordingly.
Political administrators
such as the European Commission or national governments require that the CST requirements
for the use of their citizens are fulfilled. They need a standards apparatus to ensure
that this can be achieved in a non-monopolistic market in a economically viable and inter-operable way. They also require overviews of the technology so they can
fund what is necessary to ensure the fulfilment of the citizens' requirements.
Procurers, manufacturers, application developers, and service providers
require the standards and possibly guides of using these, and also information on
available standards and new work.
User organizations and professionals
require standards to fulfil the requirements of the people they work for. For them,
overviews of needed standards and guides are essential to avoid gaps.
Many standardization efforts will thus need to satisfy a number of user audiences and the diverse audiences may make it more difficult to reach consensus.
The first basic task is reading. Clearly many other applications, if not all, involve
this. Thus, information retrieval of all kinds, from public information sources such
as signs and notices, transport departure and arrival boards, timetables, electronic data bases and news sources, teletext, etc., all require perception and above all
comprehension of the displayed text images.
The second basic task is writing. Interactive tasks, where users have a requirement
to input characters from a keyboard, offer an additional complication, and users
must be offered a familiar character set, which they must be able to recognise, or
the instructions on how to enable it. User interface design is outside the scope of this
work and much design guidance material is available, including that on characters.
Character encoding has evolved to facilitate transliteration, or the representation
of spelling in characters of another language, and conversion. With time this has
satisfied more and more of the users needs, but the field is constantly expanding.
Many coding schemes have been employed and their requirements are discussed in clause 7.
Transliteration and transcription are used when the letters of the original text are
unavailable or incomprehensible for most readers. In bibliographical or other scholarly
work the need for an exact representation of the original text calls for transliteration, while transcription is used to write e.g. Greek and Russian names in books
and newspapers for the common reader. It may also be necessary to incorporate fallback
representation to avoid annoying errors when trying to write certain letters where
adequate input/output facilities are not available. In addition, a user needs to be
able to receive and convey information that may be in a convention or notation peculiar
to a particular nationality or culture (including business or scientific sub-cultures).
The following are areas where different notations may be used, which may be culturally
dependent (a more comprehensive treatment is given in [5]):
In all applications, messages to the user and their expected responses must be capable
of being selected in language of choice. This aspect is discussed further in clause
6.
The number of characters in the Basic Multilingual Plane (BMP) of the Universal Character
Set is 65.000 characters, but with the addition of further planes the repertoire
is expected to become up to 250.000 characters. Users will expect to be able to enter and see any or all of these characters with their equipment. This aspect is discussed
further in clause 7.
To facilitate communication and interaction outside the boundaries of their own culture
or nation, many elements of these requirements need a degree of standardization.
This is addressed in later clauses of this report. Many individual and national or
cultural requirements have already been identified, and some references to standards
in this area are attached in Annex D.
Medium priority requirements:
The development of education, business, communication and leisure together with many
other factors has led to the situation where most Europeans are able to understand
- in many cases also make themselves understood in -- more than one language.
Europe today thus finds itself in a unique situation in the developed world. In a
relatively small, relatively densely populated area many different languages and
cultures are mixed. The different languages are used in swiftly growing intercommunication
between different peoples and areas, something which puts obvious demands on the means
of communication.
The recent and ongoing upsurge in the development and use of multimedia is a striking
example of culture-dependent, software-based communication. The need for localization
of such software is an obvious one; the need for internationalization and localization of means of communication for professional purposes is of older date and becomes
more urgent by the day.
As of 1 January 1995, the European Union has three new members, bringing in two new
Union languages plus the S·mi languages into this very close co-operation.
Right now, discussions on the inclusion of the former Eastern Block European countries
are progressing apace, and even if in all likelihood it will take 5-10 years before
even the first extension of the Union is made in that direction, already business
contacts are growing fast and administrative co-operation is being discussed.
It is thus clear that from the point of view of closer co-operation, the time is very
ripe to start work on CST standardization for European needs.
b. Falling apart
In the perspective of cultural disintegration which already in several Eastern European
countries has led to conflict and even civil war, it can hardly be doubted that better
text communication facilities between the different cultural groups can only lead to better understanding and more concord.
One of the most ambitious projects, the European Nervous System (ENS) -- also known
as "Support for the Establishment of Trans-European Networks between Administrations"
- is currently encountering difficulties of practical and financial kinds, and national implementations seem uncertain.
Related to ENS are the recently made Council Decisions on "a series of guidelines
for trans-European data communications networks between administrations" and on a
Community programme to "support the implementation of trans-European networks for
the interchange of data between administrations (IDA)". These projects seem to be relatively
firmly based in all relevant authorities.
Already in use is the Co-operation in Automation of Data and Documentation for Imports/Exports
and the Management and Financial Control of the Agricultural Market (CADDIA). There
are pilot projects running in some Member States; others are being installed.
Then there is the development in the EDI area, driven primarily by the private markets
but with substantial support by the EU in the form of the TEDIS (Trade EDI Systems)
programme, now in its seventh year.
Also, of course, the Commission is perhaps the world's biggest user of translation
services and as such has far-reaching interests in tools which makes possible text
transpositions from one culture/locale to another.
Last but not least one should mention the EC White Book proposals in 1993 for substantial
investments in a European infrastructure for information and the EC Action plan for
Europe's way to the information society in 1994.
Preservation and promotion of cultural and linguistic diversity is one of the guiding
principles on which EU policy for the information society rests. The Commission (XIII-E
and III-F) will prepare in May 1995 a Communication addressing European linguistic
issues and means to stimulate the emerging language-based industry
This Communication will address the stimulation, coordination and regulatory initiatives
to be undertaken in co-operation with the member states for the creation of a linguistic
infrastructure of resources and services that improve language communication. It will also overcome language barriers hampering the development of the information
society. The measures proposed will increase the use and efficiency of information
and communication systems while contributing to the enrichment of the linguistic
diversity of Europe and reinforcing Europe's language industry. [2].
The conclusion is that the European Union is making large efforts -- and planning perhaps
even larger ones -- at creating a basis for an extensive, multi-purpose data communications
network encompassing all Member States and reaching towards prospective members. Clearly these efforts will be seriously hampered if facilities for the handling
of alphabetical and cultural differences are not in place.
In 1994, three preparatory actions on reusable language resources were launched within the LRE-programme. They are POINTER on terminology data, SPEECHDAT on spoken language resources and PAROLE on harmonized textual and lexical resources and tools. These actions are expected to lead to standards proposals in this field that the EU may
wish to develop into more formal European or international standards.
There are also other programs such as EUROTRA, TELELANG, TRANSTERM, GENELEX; EUROLANG and GRAAL that work on the linguistic problems within IT.
However, it should be pointed out that the majority of the projects are not concerned
with character sets issues, the focus lying on the linguistic aspects. Many European
languages can be written and presented by use of one single 8-bit code table, and
for that reason the character sets issue is treated as lower layer problem.
There is also some privately funded research and development aimed at providing multi-lingual services in SQL data bases in more than 50 languages simultaneously and in a heterogenous environment. The results of this work are encouraging and deserve more support since both aspects of the problem are addressed: the interchange of data coded in different character sets and the linguistic aspects of such data and information.
Practically oriented work is being done both nationally and internationally within
the European standardization framework. The CEN work described in Part 0 is one example.
In general, for reasons mainly to do with the multilingual European scene described
in 5.1 above, research is being carried out in many places in Europe which concerns
different aspects of CST.
the topic is not relevant to other parts of the world, or
for whatever reason, global standardization will not be done in the foreseeable future.
In the second case, the European results will always be used as input into ISO/IEC
if and when a corresponding project is started there.
Although Internet has made some progress on internationalization support in telecommunication
standards, the same is not true for ISO/IEC and ITU-T. Work on internationalization
for OSI purposes is done only in Directory and Virtual Terminal contexts. Basic work has been done within the framework of POSIX standardization, but there are
problems with referencing that work outside POSIX standards. And while a basis for
multilingual character set coding now exists in the form of ISO/IEC 10646 (see clause
7), much more pressure is needed in order to reach the desired extent of its implementation.
In Europe, even if the EU Member States do not always properly perceive the needs
for CST standardization, there is a forceful standardization community and there
is also the strong push and support by the Commission. The latter includes support
for investigating the actual user needs.
Some European standardization work in this area has already been started, such as
the project of standardising a register of cultural specifications. This fact, plus
the prominent position enjoyed by European researchers and technicians in the field
of CST, is a good argument for Europe taking the lead in standardization. That way, Europe should be able to sustain (and build on) its current competence as well as pull other regions along -- even if the languages and cultural factors are locally dependent,
the methodology is universally applicable.
It has been suggested that European CST standardization could include a pilot project -- perhaps a reference implementation -- exploring the practical use of ISO/IEC 10646
and also providing material for implementation guides.
It was furthermore stressed by the CST workshop (see clause 1) that close co-operation between R-and-D in this field and the standardization efforts is required.
A strong argument for not leaving non-indigenous languages outside the scope of CST
standardization, however, is the fact that there are large groups in the EU speaking
Arabic, Hindi, etc., and that those people by law have the right not to be discriminated against. Hence, the standardization bodies (and the Commission) must be prepared
to argue its case if a decision as proposed above is made and the matter is subsequently
brought to the Court of Justice.
Another argument for taking in non-European languages would be the matter of trade
and business: it makes good sense from an economical viewpoint to facilitate business
relationships by providing for localization.
However, it should be noted that standards and implementations for many "immigrant" languages and scripts are presently being developed in the home countries and regions of origin (Arabic, Indic, and East-Asian for instance). Standards bodies like CEN/TC304 should liaise with the corresponding members in those areas to facilitate provision of the necessary tools. For the present, it should remain a European priority to
accommodate Europe's indigenous languages, however large or small, since no one else
will be able to do so.
Medium priority requirements
Users want applications that are truly adapted to their cultural environment, so that
the use of the application feels completely natural with respect to the user's cultural
expectations.
Some language-dependent messages and input are commonly used, for example asking for
confirmation or rejection (yes/no/cancel?), and may be standardized.
A vast majority of messages, however, will be defined by the specific application.
The best solution here would be to help applications administer messages/input according
to the different languages and cultures, and to give users mechanisms to supply their own input to the application. A standard for users (or national distributors or
user consultants) to specify input and messages for a given application would advance
the availability of customized man-machine dialogue significantly.
As guidance for the use of a consistent terminology in a language, a recommended list
of IT-related terms in each language could prove very useful.
In essence the user requires that the man-machine dialogue is in a language that he
can understand, normally his own language. If the dialogue is available only in other
languages, then it is a requirement that a natural language translator be present.
This will also facilitate communication between people not having a common communication
language.
To have all applications issuing messages and accepting input in all languages of
the world seems to be a large problem and a difficult task.
Machine translation services give an additional dimension to these problems.
To satisfy fully the user requirements in all applications may take a long time. It
is desirable that the user gets the best possible service in the meantime. This may
be accomplished by specifying preferences for alternatives, for example messages
in another language when support for the preferred language is not available. The other
example is the provision of an alternative representation if the equipment available
is not capable of correctly presenting the characters. The internationalization model
needs to be enhanced to provide fallback representation, and APIs need to be specified
for the fallback support.
Another problem is that, for a number of cultures, data are not available. Reliable
data are hard to obtain. A specified process would help. CEN/TC304 is currently working
on a standard for registration of such data. National work on collecting and obtaining consensus on cultural data should be encouraged.
When reliable data are available, they should be uniquely identifiable world-wide
and easily accessible. Then any software producer could get hold of the information,
and every user would be able to know and specify precisely what behaviour is wanted.
The data should be available in a formally specified form and electronically, so that
applications could process them without change (possibly via operating system services)
and automatically deliver the desired support. The forthcoming CEN Cultural Register Standard provides a means for this.
For the use of the POSIX locales and charmaps, reference to the Cultural Register
should be built into the standards concerned; examples include:
This should be done at the ISO level, and it is therefore desirable that the forthcoming
CEN cultural register standard be further developed into an ISO/IEC standard.
Such guidance for the design of programming languages is the subject of a revision of ISO/IEC TR 10176. Guidelines for APIs for cultural conventions and Programming language independent APIs are the subjects of ISO internationalization projects in ISO/IEC JTC1/SC22/WG20.
A short list of coded character sets currently in use includes the 7-bit ISO/IEC 646,
its predecessor ASCII, other national variants of ISO/IEC 646, the 8-bit ISO 8859
series (regional sets covering e.g. Eastern and Western European languages, Greek
and Arabic), ISO 6937 (covering the Latin script in an 8/16 bit code), the Japanese, Chinese
and Korean 14-bit sets (JIS X0208 and X0212, GB 2312 and KSC 5601, respectively).
The only standardized coded character set which is intended to cover all languages
of the world is the recent ISO/IEC 10646, also known as the Universal Multiple-Octet
Coded Character Set, or UCS. In order to satisfy that purpose, however, it is necessary to use different codes and different levels of support. The standard is still being
extended, but with some 33.000 characters it covers most of the languages in use
today.
There are also a myriad of non-standard character sets developed by manufacturers
to cover the same needs. Notably IBM has been creative, with a family of EBCDIC character
sets (foremost among those incompatible with ISO/IEC 646) and PC code pages.
The X.400 applications supports the 8-bit coding systems defined by ISO 6937 and any
set specified in the ISO/IEC character set registry. The X.500 Directory Service
uses the T.61 (ISO 6937) coding, which caters for almost all characters used by Latin
alphabet languages.
Recently, new objects have been introduced in the Directory Service which make internationalization
and language specification possible, but as yet no applications with these new features
exist. Since June 1992, the Internet also has the means to exchange messages containing multiple character sets through the methods defined in the specification
of MIME (Multiple-purpose Internet Mail Extension). The World Wide Web service now
has started to implement the underlying protocol HTTP, based on 8-bit character coding.
Nevertheless, the user ideally should perceive that the character set interface of
his choice is the same all over the world, regardless of region or country where
the data originated, and without intrusion of any underlying technical complexities
of communication service or application program.
There is therefore a major need for conversions between all existing coded character
sets. UCS is the primary building block for this, since it will encompass all the
other character sets. Its implementation will provide the required integrity of characters as well as the required support for multi-linguality in the advanced network services.
Thus despite some promising signs, Europe and the rest of the world are still of mixed
opinions regarding the use of character sets. The users still use equipment based
on 8-bit coding, the telematic services do not widely implement UCS, and the old
standards are still implemented.
Some of the major reasons for the lack of UCS implementations are the following:
Despite this, one property of the existing IT applications is encouraging, namely
that some of the current and most important telematic services have the capability
to transport a large number of different character sets, including UCS.
a) Input
It is expected that input in the future be generated on keyboards not very different
from current keyboards, which have about 100 individual keys. There is a user requirement
for standards for generating UCS characters with only a limited set of keyboard keys. These standards are currently varying from culture to culture, and standardization
should cater for this cultural variance, while also offering one or more globally
standardized input methods for UCS. The keyboard WG of ISO (ISO/IEC SC18/WG9) has
recently started a new project assigned on the issue of global input method standards,
while the CEN cultural registration standard can cater for registering culturally
dependent input methods.
b) Processing, communication and storage
The different encoding forms and levels of UCS have different properties and also
requirements for support by the application. Applications are usually written in
a programming language and require the support by an operating system, and it is
thus essential for proper programming and portability of applications that programming languages
and operating systems support the various encoding forms and levels of UCS. The ISO
group on programming languages, operating systems and programming environments (ISO/IEC JTC1/SC22) has several projects that address the issue of UCS support in the operating
system, including POSIX, an internationalization framework technical report, a guide
on the design of programming languages and language independent APIs for internationalization.
Communications standards need to be upgraded to be able to handle the different forms
and levels of UCS, in a similar way to the operating systems and programming languages
described above.
As the different encodings and levels of UCS have different capabilities and strong
and weak points, UCS can be expected for as long as we can see to be present in different
forms, and a requirement to be able to handle conversion between these coding forms is a major one. Specifications of these conversions are included in the standard,
but the capabilities need to be present in applications to prevent users from having
problems. Software for this conversion between UCS encodings is freely available.
A related issue is the conversion to and from smaller character sets, which is covered
in clause 7.4.2.
Getting applications to support UCS is thus a major goal. This cannot be controlled
by standards authorities or public authorities, but progress can be helped by public
procurement requirements and publicly funded programmes for development and awareness.
c) Output
There are a number of output requirements for the support of UCS:
Equipment, including printers and display devices, should be capable of displaying
all UCS characters and need to handle UCS combined characters correctly.
The requirement of full output support can be expected to not be fulfilled in many
cases. The availability of glyphs and fonts may be quite limited due to hardware
limitations etc., and the evolution of UCS with additions of new characters may render
equipment out-of-date. The definition of European subsets of UCS will solve this problem
for most equipment, assuming that fonts for the subset(s) will be made available
in the public domain.
For older and less advanced equipment, rules are needed for fallback rendition of non-displayable characters. Such rules should be designed in a forward-compatible (future-enabling) way.
Most users of IT would not be capable of precisely identifying or understanding all UCS characters (estimated to exceed 250.000), and ways to convey the meaning of characters need to be present. Many users would only be able to recognize a limited number of scripts and other characters need then to be transliterated to the relevant scripts to be understood by the reader. This transliteration may be culturally dependent (= transcription), and there may also be global transliteration specifications. ISO has produced a few standards, mainly for bibliographic purposes. CEN/TC304 has started work on transliteration, but further work needs to be done on how to specify cultural transcription and fallback rules.
Another requirement is to exactly identify a character, and possibly get information
on where, how, and why it is used. The ISO/IEC JTC1/SC2/WG3 character set group is
currently working on establishing a database with such information, and the ISO/IEC
JTC1/SC18/WG9 keyboard group is also working on specifying the user interface related
to this issue. Further procedures for formulating queries on such information could
be specified, maybe in conjunction with the above fallback and transliteration services.
Even if such a database is set up, reliable information on European characters must be collected by Europeans. To ensure the quality of this information, sponsored European research work is needed.
d) Subsets of UCS
Some of the implementation problems discussed above could be solved by the provision
of subsets of UCS. CEN/TC304 has already started work on defining European subsets,
particularly aimed at solving the problems of outputting the full character set of
UCS.
It is estimated that full UCS implementation will be costly in the first stages of
UCS use, and that manufacturers then only will implement a subset. To ensure that
a common subset which can be used by the vast majority of European users be available
for a reasonable price, and as a guide to manufacturers, it will be helpful to users and
procurers of systems if European subsets of UCS, encompassing all characters for
use in European languages plus other frequently used characters, be specified. Also
such subsets may be useful to do further standardization work for example on sorting, so
that the work is reasonably limited and still useful in an European environment.
Only a small number of subsets should be specified. CEN is currently working on such
European subsets of UCS.
Fallback methods
Inherent in the specification of character set conversion is how to handle inconvertible
characters, including information preserving and information losing fallback techniques,
and as different requirements may be present, it can be expected that different solutions be needed. One requirement is information preserving fallback, where
the fallback representation would be legible to the user in the character set available,
and where fallback representation is only done when needed, thus not disabling the
user further from the limited character set. Another requirement is the preservation
of the number of characters, but possibly information-losing.
This work is being investigated by different groups, e.g. CEN/TC304/WG4, IETF and
TERENA. All this work needs to be brought together in a single set of specifications.
The linguistic aspects can easily get lost in structures such as Fora, Consortia and
ad-hoc developments of publicly available specifications. This kind of structure
may counteract a true multilingual infrastructure in Europe.
The single workshop approach is not in itself a threat to a true multilingual infrastructure
in Europe, as long as the proper management tools are in place.
For minority cultural groups, national bodies may not be the best channel to get heard
internationally, so other means must be found as well, which do not exist today.
This is valid also for communication with and among disabled people. For this case, there is need for support from other ways of input and output of common languages or specific languages suiting other ways of perception and production. Examples are the symbolic language BLISS and natural sign languages. For the industry to be able to supply products suiting these requirements, the CST standardization must include them in the common work.
Examples of such services and products are
The industry needs coordinated registration procedures at the European level.
Solutions are also needed to related problems such as
Existing IT standards which include or presuppose the use of coded character sets need to be updated to cater to the use of UCS.
In addition, means for code transformation between different coding methods in user
equipment and telematic services must be provided either in the user environment
or in the services. The use of a European UCS subset must be taken into account.
A particular way of handling the coexistence problem is the fallback representation. Proper methods for transcription/transliteration also taking into account the needs of disabled and elderly people must be provided.
-a taxonomy helps to identify all aspects of the domain in question which might be
subject to standardization;
-a taxonomy helps to provide a logical structure for the standardization activity.
A taxonomy has been developed of relevant concepts in the domain of character-set
technology, based on user requirements for functionality, as discussed in Clause
4 of Part I of this report.
By way of an application, all known current standards and standardization activities have been grouped according to this taxonomy, thus forming another type of taxonomy, that of the standards themselves.
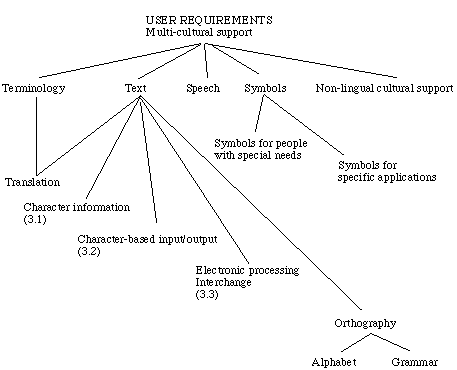
Figure 1: Topical map of user requirements in CST
The present classification of CST concepts was made through the identification of
commonalties, such as characters, sets, fonts and rules relating to presentation.
The analysis was based on a much wider view of "multi-cultural support", a shown
in Figure 1, which attempts to map some of its concepts. Areas relevant to this report were
chosen and developed into the full taxonomy, shown in clause 3.2. This latter choice
comprises the technology which relates to methods for specifying, and rules governing,
the creation of unique properties and codes which facilitate the presentation, storage
and transmission of individual characters.
The taxonomy in clause 3.2 was based on references ISO/IEC TR 10000-1, ISO TR 12382 and IEC 824 and the activities of appropriate standardization bodies, but most notably the work of CEN/TC304 and ISO/IEC/JTC 1.
The taxonomy in clause 3.2 takes the classic form of a tree structure, where two major
classes are recognized; Locales and Characters. The former deals with the cultural
environment of the user, the latter with the smallest divisible parts that make up
the messages which are being electronically processed.
A taxonomy of whatever phenomena can be constructed in several ways, depending on
its purpose and the aspects applied. (For instance, a number of persons may be grouped
firstly according to age, then according to gender, then according to place of living
-- or precisely the other way around, according to need.) A taxonomy for standardization
purposes naturally has to take into account the most practical ways to group existing
standards and standardization projects as well as the logical connections between them and any conceptual "holes" which may need to be filled in order to cover the
full need for standardization.
The following taxonomy is thus intended to provide a map for almost all of the user
requirements identified in Part I (see the application in Part III). Therefore the
level of subordination in some cases go very deep -- this does not mean that the
actual standardization projects need a taxonomy of the same complexity. When a sub-level
is empty of existing or future standards, the entries in that sub-level are simply
collapsed and only the level above remains.
L/ LOCALES
|----- L/1 Specifications
| |----- L/11 Languages
| | |----- L/111 Natural languages
| | |----- L/1111 Vocabulary
| | | |----- L/11111 Standard terminology
| | | |----- L/11112 Thesauri
| | | |----- L/11113 Standard phrases
| | | |----- L/11114 Translation
| | |----- L/1112 Grammar
| | |----- L/1113 Orthography
| | | |----- L/11131 Alphabet
| | | |----- L/11132 Spelling
| | | |----- L/11133 Use of special characters
| | | |----- L/11134 Capitalization
| | | |----- L/11135 Hyphenation
| | | |----- L/11136 Punctuation
| | | |----- L/11137 Transcription
| | | |----- L/11138 Ordering
| | | | |----- L/111381 Europe
| | | | |----- L/111382 World-wide
| | | |----- L/11139 Personal names and titles
| | |----- L/1114 Speech
| |----- L/12 Cultural conventions
| | |----- L/121 Cultural elements
| | |----- L/1211 Orthography
| | | |----- L/12111 Date and time format
| | | |----- L/12112 Numeric separators
| | | |----- L/12113 Monetary format
| | | |----- L/12114 Telephone number format
| | | |----- L/12115 Payment number format
| | | |----- L/12116 Mail address format
| | | |----- L/12117 National places
| | |----- L/1212 Measurement system
| | |----- L/1213 Layout styles
| | |----- L/1214 Paper sizes
| |----- L/13 Operating system dependency
| |----- L/131 POSIX
| | |----- L/1311 Europe
| | |----- L/1312 World-wide
| |----- L/132 Other
|----- L/2 Registration
| |----- L/21 Procedures
| |----- L/211 Europe
| | |----- L/2111 National
| |----- L/212 World-wide
|----- L/3
Implementation
|----- L/31 Fallback
C/ CHARACTERS
|----- C/1 Character information
| |----- C/11 Identification
| | |----- C/111 Characters
| | | |----- C/1111 Identifiers
| | | |----- C/1112 Attributes
| | |----- C/112 Repertoires
| | | |----- C/1121 Graphic characters
| | | | |----- C/11211 Natural language alphabets
| | | | | |----- C/112111 Europe
| | | | | | |----- C/1121111 General
| | | | | | |----- C/1121112 Disabled/elderly
| | | | | |----- C/112112 World-wide
| | | | |----- C/11212 Programming language alphabets
| | | | |----- C/11213 Non-alphabetic symbols
| | | | |----- C/112131 General
| | | | |----- C/112131 Disabled/elderly
| | | |----- C/1122 Control functions
| | | | |----- C/11221 Europe
| | | | | |----- C/112211 General
| | | | | |----- C/112212 Disabled/elderly
| | | | |----- C/112222 World-wide
| | | |----- C/1123 Registration
| | |----- C/113 Glyphs
| | | |----- C/1131 Registration
| | | |----- C/1132 Character correspondence
| | |----- C/114 Glyph repertoires
| | |----- C/1141 Registration
| | |----- C/1142 Repertoire correspondence
| |----- C/12 Manipulation
| |----- C/121 Transformation
| |----- C/1211 Case conversion
| |----- C/1212 Transliteration
| |----- C/1213 Fallback representation
|----- C/2 Input/output
| |----- C/21 Input
| | |----- C/211 Keyboard
| | | |----- C/2111 Europe
| | | |----- C/2112 World-wide
| | |----- C/212 Other means
| |----- C/22 Output
| |----- C/221 Character repertoires
| | |----- C/2211 Europe
| | |----- C/2212 World-wide
| |----- C/222 Character attributes
|----- C/3 Electronic processing
|----- C/31 Coding schemes
| |----- C/311 Encoding of graphic characters
| | |----- C/3111 7-bit method
| | |----- C/3112 8-bit method
| | |----- C/3113 Multiple-octet method
| | |----- C/31131 Europe
| | |----- C/31132 World-wide
| |----- C/312 Encoding of control functions
| |----- C/313 Code transformations
| |----- C/3131 UCS--UCS
| |----- C/3132 UCS--other coding schemes
| | |----- C/31321 Europe
| | |----- C/31322 World-wide
|----- C/32 Interchange/communication
| |----- C/321 7-bit method
| |----- C/322 8-bit method
| |----- C/323 Multiple-octet method
|----- C/33 Internationalization support
|----- C/331 Programming languages
| |----- C/3311 Language-dependent
| |----- C/3312 Language-independent
|----- C/332 Operating systems
|----- C/333 Communications
|----- C/3331 Directory services
|----- C/3332 Telematics
| Code | Title | Current standardization or research activity |
| / (no id) | TAXONOMY OF CST AND INTERNATIONALIZATION | CEN/TC304 |
| L/ | LOCALES | - |
| L/1 | Specifications | - |
| L/11 | Languages | - |
| L/111 | Natural languages | - |
| L/1111 | Vocabulary | ISO/TC 37, LRE - TRANSTERM, GENELEX |
| L/11111 | Standard terminology | LRE - POINTER |
| L/11112 | Thesauri | - |
| L/11113 | Standard phrases | - |
| L/11114 | Translation | LRE - PAROLE, EUROTRA |
| L/1112 | Grammar | - |
| L/1113 | Orthography | - |
| L/11131 | Alphabet | CEN/TC304/WG2 |
| L/11132 | Spelling | - |
| L/11133 | Use of special characters | - |
| L/11134 | Capitalization | - |
| L/11135 | Hyphenation | - |
| L/11136 | Punctuation | - |
| L/11137 | Transcription | - |
| L/11138 | Ordering | - |
| L/111381 | Europe | CEN/TC304/WG1 |
| L/111381 | World-wide | ISO/IEC/JTC1/SC22, ISO/TC46, ISO/TC37 |
| L/11139 | Personal names and titles | - |
| L/1114 | Speech | LRE - EAGLES, LRE - SPEECHDAT |
| L/12 | Cultural conventions | ISO/IEC JTC1/SC22/WG20, X/Open, CEN/TC304/WG2 |
| L/121 | Cultural elements | - |
| L/1211 | Orthography | - |
| L/12111 | Date and time format | - |
| L/12112 | Numeric separators | - |
| L/12113 | Monetary format | - |
| L/12114 | Telephone number format | PTTs, CEPT, ENO |
| L/12115 | Payment number format | - |
| L/12116 | Mail address format | CEN/PC8 |
| L/12117 | National places | - |
| L/1212 | Measurement system | - |
| L/1213 | Layout styles | - |
| L/1214 | Paper sizes | ISO/TC6, CEN/TC172 |
| L/13 | Operating systems dependency | - |
| L/131 | POSIX | - |
| L/1311 | Europe | - |
| L/1312 | World-wide | ISO/IEC JTC1/SC22/WG15 |
| L/132 | Other X/open | - |
| L/2 | Registration | - |
| L/21 | Procedures | - |
| L/211 | Europe | CEN/TC304/WG2 |
| L/2111 | National | - |
| L/212 | World-wide | - |
| L/3 | Implementation | - |
| L/31 | Fallback | - |
| C/ | CHARACTERS | - |
| C/1 | Character information | - |
| C/11 | Identification | - |
| C/111 | Characters | ISO/IEC JTC1/SC2, SC18 |
| C/1111 | Identifiers | - |
| C/1112 | Attributes | - |
| C/112 | Repertoires | ISO/IEC JTC1/SC2, SC18, SC22 |
| C/1121 | Graphic characters | - |
| C/11211 | Natural language alphabets | - |
| C/112111 | Europe | CEN/TC304/WG3 |
| C/1121111 | General | - |
| C/1121112 | Elderly/disabled | ISO/TC173 |
| C/112112 | World-wide | - |
| C/11212 | Programming language alphabets | - |
| C/11213 | Non-alphabetic symbols | - |
| C/112131 | General | - |
| C/112132 | Disabled/elderly | TIDE |
| C/1122 | Control functions | - |
| C/11221 | Europe | - |
| C/112211 | General | - |
| C/112212 | Elderly/disabled | - |
| C/11222 | World-wide | - |
| C/1123 | Registration | - |
| C/113 | Glyphs | ISO/IEC JTC1/SC18 |
| C/1131 | Registration | - |
| C/1132 | Character correspondence | - |
| C/114 | Glyph repertoires | ISO/IEC JTC1/SC18 |
| C/1141 | Registration | - |
| C/1142 | Repertoire correspondence | - |
| C/12 | Manipulation | - |
| C/121 | Transformation | CEN/TC304/WG4 |
| C/1211 | Case conversion | ISO/IEC JTC1/SC22/WG15, WG20 |
| C/1212 | Transliteration | ISO TC46 (bibliographic) |
| C/1213 | Fallback representation | - |
| C/2 | Input/output | - |
| C/21 | Input | ISO/IEC JTC1/SC18 |
| C/211 | Keyboard | - |
| C/2111 | Europe | - |
| C/2112 | World-wide | - |
| C/212 | Other means | - |
| C/22 | Output | - |
| C/221 | Character repertoires | - |
| C/2211 | Europe | - |
| C/2212 | World-wide | - |
| C/222 | Character attributes | - |
| C/3 | Electronic processing | - |
| C/31 | Coding schemes | ISO/IEC JTC1/SC2, SC22; CEN/TC 304/WG3 |
| C/311 | Encoding of graphic characters | ISO/IEC JTC1/SC18 (text layout) |
| C/3111 | 7-bit method | CEN/TC304/WG3 |
| C/3112 | 8-bit method | CEN/TC304/WG3 |
| C/3113 | Multiple-octet method | CEN/TC304/WG3 |
| C/31131 | Europe | - |
| C/31132 | World-wide | - |
| C/312 | Encoding of control functions | ISO/IEC JTC1/SC18 (control functions) |
| C/313 | Code transformations | CEN/TC304/WG4 |
| C/3131 | UCS--UCS | - |
| C/3132 | UCS--other coding schemes | - |
| C/31321 | Europe | - |
| C/31322 | World-wide | - |
| C/32 | Interchange/communication | - |
| C/321 | 7-bit method | EWOS: Use of ISO 2022 coding structure |
| C/322 | 8-bit method | EWOS: Use of ISO 2022 coding structure |
| C/323 | Multiple-octet method | EWOS: Use of ISO 10646 coding structure |
| C/33 | Internationalization support | LRE - GLOSSASOFT, ISO/IEC JTC1/SC22/WG15 and WG20 |
| C/331 | Programming languages | - |
| C/3311 | Language-dependent | - |
| C/3312 | Language-independent | - |
| C/332 | Operating systems | - |
| C/333 | Communications | - |
| C/3331 | Directory services | - |
| C/3332 | Telematics | - |
Research and development related to CST standardization could be included in the EC
Commission's IV Framework programme.
See also Part IV.
The descriptions of work items and programmes in Part IV have been made with this in mind. However, constant vigil is necessary if the required awareness is to be built and maintained.
Promotion, coordination, research and development activities, based on the discussion
in Part III, are outlined in clauses 2 and 3.
In clause 4, the requirements in Part I are grouped according to the taxonomy in Part
II. The items in clause 4 are then in clause 5 subdivided according to status: completed
or ongoing work and new work to start now or later.
New work items are described in clauses 6 9. Each clause is related to the organization
which is recognized as the one mainly responsible for the respective technical area.
Finally the financial aspects are discussed in clause 10.
Fora for the dissemination of information on standardization work and to obtain user
input have proven useful. Regular workshops is another way of providing user interface.
R-and-D projects for the development of reference implementation is one way to increase
the practicability of the standards. Support of such projects could be given over
the normal R-and-D programmes in the EU.
CEN/TC304 is expected to develop such proposals into formal standards. This is reflected in the standardization programme below.
The problem of character sets appears with all its dimensions when the products are
put on the network and included in the telematic service. In telematic services,
the minimum common denominator is still ISO 646 with some minor exceptions i.e. in
electronic mail, where 8-bit character sets codes are used.
For this reason the scope of the R-and-D work in developing and implementing Character
Sets Technology and Cultural Conventions for IT is in the CST taxonomy class C/3332
(Internationalization support in Telematics). This would provide multi-cultural support
facilities in the telematic services which are now under development in Europe (ENS
programme is just one of them).
The scope of the R-and-D work should be in specifying, implementing and developing:
| Code | Title | Action | P h a s e | User requirement | ||
| - | - | - | - | Standardization | Other | |
| / (no id) | TAXONOMY | a) Publish it b) Maintain it | 1 4 | - | - | |
| L/ | LOCALES | - | - | - | - | |
| L/1 | Specifications | - | - | - | 6B3, 6B13: The availability and use of cultural specifications should be promoted | |
| L/11 | Languages | - | - | - | - | |
| L/111 | Natural languages | - | - | - | - | |
| L/1111 | Vocabulary | - | - | - | - | |
| L/11111 | Standard terminology | National translation of IT-terminology | 4 | 6B6: Standardized IT terminology (per language) | - | |
| L/11112 | Thesauri | Terminological data exchange format | 4 | - | R-and-D (Transterm, Genelex and Pointer) | |
| L/11113 | Standard phrases | a) Standardized interface with localizers b) Guidelines and procedures for development of internationalized software products | 4 3 | 6B8: API standard for dialogue interface 4A7: Application prompts for appropriate orthography/notation 6B14: IT standards to be enhanced to support internationalization | R-and-D (Glossasoft) 4A8: Applications to implement dialogue with user in language of choice | |
| L/11114 | Translation | Harmonized textual and lexical resources and tools (for automatic translation) | 4 | 6B12: Standard for machine translation | R-and-D (Parole) | |
| L/1112 | Grammar | see L/1114 | - | 6B12: Standard for machine translation | R-and-D | |
| L/1113 | Orthography | - | - | - | - | |
| L/11131 | Alphabet | Technical report on repertoires of the indigenous languages of Europe | 1 | - | 7B10: Research on history and use of European characters. | |
| L/11132 | Spelling | - | - | - | - | |
| L/11133 | Use of special characters | - | - | - | - | |
| L/11134 | Capitalization | - | - | - | - | |
| L/11135 | Hyphenation | - | - | - | - | |
| L/11136 | Punctuation | - | - | - | - | |
| L/11137 | Transcription | - | - | - | - | |
| L/11138 | Ordering | - | - | - | - | |
| L/111381 | Europe | a) Standard ordering of the minimum European subset b) Standard ordering of all European characters | 1 2 | 6B17: Standard for "European" ordering | - | |
| L/111382 | World-wide | Standard for deterministic ordering of all UCS characters | 4 | 6B15b: Standard for default ordering of UCS characters | - | |
| L/11139 | Personal names and titles | - | - | - | - | |
| L/1114 | Speech | Models of spoken language | 4 | - | R-and-D (Speechdat) | |
| L/12 | Cultural conventions | - | - | - | - | |
| L/121 | Cultural elements | - | - | - | - | |
| L/1211 | Orthography | - | - | - | - | |
| L/12111 | Date and time format | - | - | - | - | |
| L/12112 | Numeric separators | - | - | - | - | |
| L/12113 | Monetary format | - | - | - | - | |
| L/12114 | Telephone number format | - | - | - | - | |
| L/12115 | Payment number format | - | - | - | - | |
| L/12116 | Mail address format | - | - | - | - | |
| L/12117 | National places | - | - | - | - | |
| L/1212 | Measurement system | - | - | - | - | |
| L/1213 | Layout styles | - | - | - | - | |
| L/1214 | Paper sizes | - | - | - | - | |
| L/13 | Operating system dependency | - | - | - | - | |
| L/131 | POSIX | - | - | - | - | |
| L/1311 | Europe | Standard for European locale | 3 | 6B2: Standard for European locale | - | |
| L/1312 | World-wide | Update POSIX to cover more cultural conventions | 4 | 6B1: Extend formal specification techniques to cover more classes of cultural conventions | - | |
| L/132 | Other | Formal specification techniques for cultural data | 4 | 6B13: Standard for specification of cultural data independent of POSIX | - | |
| L/2 | Registration | - | - | - | - | |
| L/21 | Procedures | - | - | - | - | |
| L/211 | Europe | a) European Cultural Register (ENV) b) Technical report on unregistered cultural conventions | 1
2 | 6A3: Registration procedures | 6B9: Central process to collect data from National
Bodies 7B6: Encourage registration by CEN | |
| L/2111 | National | a) National standards on cultural conventions b) Guidelines on nat-ional specifications of cultural conventions | 3
3 | 6A2: National Bodies to collect cultural data | 6A4: Guidelines on the specification of cultural conventions | |
| L/212 | World-wide | International cultural registry (EN) | 3 | 6B5: Transform European registration procedures into global ones | - | |
| L/3 | Implementation | - | - | - | - | |
| L/31 | Fallback | Update POSIX to include fallback locales | 4 | 6B7: Enhance formal specification techniques to allow for fallback locales | - | |
| C/ | CHARACTERS | - | - | - | - | |
| C/1 | Character information | - | - | - | - | |
| C/11 | Identification | - | - | - | - | |
| C/111 | Characters | - | - | - | 4B9: User manual on purpose and use of all UCS characters. Priority: Europe. | |
| C/1111 | Identifiers | Short identifiers for characters | 4 | - | 6B8: Applications to permit identification of all characters. | |
| C/1112 | Attributes | - | - | - | - | |
| C/112 | Repertoires | Revision of R-IT-04 | 2 | - | 7B11: Guidelines on use of char. sets in Europe | |
| C/1121 | Graphic characters | a) Transpose UCS into EN b) Update UCS to include missing European characters c) Maintenance of UCS | 3 4 3 | 7A1: Standard on all European characters | 4B7: Access to all characters of UCS 7C1: Applications to handle all UCS characters | |
| C/11211 | Natural language alphabets | - | - | - | - | |
| C/112111 | Europe | Standard on minimum European subset(s) | 1 | 7A8: Definition of European
subsets of ISO/IEC 10646-1 4B6: Symbols to be available to users | - | |
| C/1121111 | General | - | - | - | - | |
| C/1121112 | Disabled/elderly | 8-bit Braille character set | 3 | 4A5: Char.sets and control code reps should be developed to cater for the needs of disabled | - | |
| C/112112 | World-wide | - | - | - | - | |
| C/11212 | Programming language alphabets | - | - | - | - | |
| C/11213 | Non-alphabetic symbols | - | - | - | - | |
| C/112131 | General | - | 4 | - | - | |
| C/112132 | Disabled/elderly | General symbol language representation | 3 |
4B2: Applications to include symbol language (Bliss or similar) 4A4: Standard on min. symbols subset for disabled and elderly | - | |
| C/1122 | Control functions | - | - | - | - | |
| C/11221 | Europe | - | - | - | - | |
| C/112211 | General | Standard on minimum European subset of control functions | 4 | - | - | |
| C/112212 | Disabled/elderly | - | - | - | - | |
| C/11222 | World-wide | - | - | - | - | |
| C/1123 | Registration | - | - | - | - | |
| C/113 | Glyphs | a) Character-glyph model for Europe b) International Char-glyph model | 3 4 | 4A2: Permit selection of a variety of glyphs/ repertoires/ fonts/sizes | - | |
| C/1131 | Registration | - | - | - | - | |
| C/1132 | Character correspondence | Character-glyph correspondence for Europe | 3 | 4A2: Permit selection of a variety of glyphs/ repertoires/ fonts/sizes | - | |
| C/114 | Glyph repertoires | Enhanced OCR-B std. for European use | 4 | 7B13: Enhanced OCR-B is needed for Europe | - | |
| C/1141 | Registration | - | - | - | - | |
| C/1142 | Repertoire correspondence | - | - | - | - | |
| C/12 | Manipulation | - | - | - | - | |
| C/121 | Transformation | - | - | - | - | |
| C/1211 | Case conversion | - | - | - | - | |
| C/1212 | Transliteration | Technical report on transliteration in Europe | 2 | 4B4: Applications to provide transliteration possibilities | - | |
| C/1213 | Fallback representation | a) Fallback to ASCII b) General European rules for fallback | 2 3 | 4A6, 7B4, 7B8: Specifications to be provided, including characters as yet undefined | - | |
| C/2 | Input/output | Input/output devices for disabled and elderly people | 3 | 4A3: Facilities should cater
to disabled and elderly people 4A4: Standard on min. symbols subset for disabled and elderly 4A5: Char.sets and control code reps should be developed to cater for the needs of disabled | - | |
| C/21 | Input | - | - | - | - | |
| C/211 | Keyboard | - | - | - | - | |
| C/2111 | Europe | a) Standardized profile of UCS keyboard for Europe b) Transpose ISO/IEC 9995 into EN | 3 3 | 4B7: Permit users to generate and see all UCS characters 7A3: Keyboard standard for all European characters | - | |
| C/2112 | World-wide | - | - | 7C2: Keyboard standard(s) for all UCS characters | - | |
| C/212 | Other means | - | - | - | - | |
| C/22 | Output | - | - | - | - | |
| C/221 | Character repertoires | - | - | - | - | |
| C/2211 | Europe | see C/1213 and C/112111 | - | 7A7: Output media to be able to handle all European UCS characters | - | |
| C/2212 | World-wide | - | - | 7C3: Output media to be able to handle all UCS characters | - | |
| C/222 | Character attributes | see C/1213 and C/112111 | - | 4A2: Output media to be able to handle many fonts and sizes | - | |
| C/3 | Electronic processing | - | - | - | - | |
| C/31 | Coding schemes | - | - | - | - | |
| C/311 | Encoding of graphic characters | Bar coding of European characters | 4 | 7B12: Bar code standard for European use needed | - | |
| C/3111 | 7-bit method | Inter-working with Telex | 1 | - | - | |
| C/3112 | 8-bit method | 8-bit sets for Europe | 1 | (Coexistence) | - | |
| C/3113 | Multiple-octet method | see C/323 | 2 | 7B1b: Guidance on design on language-independent API in relation to UCS | 7A11: Promotion of use of UCS 7A2: Implementation of UCS 7B2: Application support of UCS to be encouraged by R-and-D, public procurement | |
| C/31131 | Europe | see C/11211 | - | 7A8: European subset of UCS | - | |
| C/31132 | World-wide | - | - | - | - | |
| C/312 | Encoding of control functions | - | - | - | - | |
| C/313 | Code transformations | Technical report on tools and transformation tables | 4 | 7B9: All code transformation standards to be compatible | - | |
| C/3131 | UCS--UCS | Guide on conversion between UCS options | 3 | 7A6: Standards for transformations between different UCS options. -- Priority: UCS-2, UCS-4, UTF-8 | - | |
| C/3132 | UCS--other coding schemes | Model for transformations between European coded character sets | 2 | 7A10: Standards for transformations between UCS options and other encodings. | - | |
| C/31321 | Europe | - | - | - | - | |
| C/31322 | World-wide | - | - | - | - | |
| C/32 | Interchange/communication | - | - | - | - | |
| C/321 | 7-bit method | see C/322 | - | - | - | |
| C/322 | 8-bit method | Guidance on ISO 2022 | 0 | - | - | |
| C/323 | Multiple-octet method | Use of the ISO/IEC 10646 code structure | 2 | 7A5: Communication standards to support UCS | - | |
| C/33 | Internationalization support | - | - | - | 4A1: Applications to allow use of full orthography in language of
choice 4A9: Public IT services to allow use of any language | |
| C/331 | Programming languages | Guidelines for UCS in programming languages | 3 | 7A4: Programming languages and operating systems should support UCS alphabets | 7B1a: Guidelines for design in relation to UCS | |
| C/3311 | Language-dependent | a) Support for UCS in programming languages b) Guidelines for the design of internation-alization | 4
3 | - | 6B10: Guidelines on internationalization functionality in programming languages | |
| C/3312 | Language-independent | Language-independent API specification | 4 | 6B15a: Language-independent API specification for internationalization | - | |
| C/332 | Operating systems | Support for Locales in POSIX operating systems | 3 | 7A4: Programming languages and operating systems should support UCS alphabets | - | |
| C/333 | Communications | - | - | - | - | |
| C/3331 | Directory services | Introduction of locales in ISO standard on The Directory | 3 | 6B4: Reference to the Cultural Register to be built into relevant IT standards | - | |
| C/3332 | Telematics | Multi-cultural support in various application standards: a) ETSI guide c) DVB d) Videotex e) Radio Paging f) GSM text comm. g) MHS h) ODA i) SGML j) RDS k) HBES l) IC-cards m) Traffic Telematics n) Medical Informatic o) Techn. draw+doc p) Library Informatics | -
3 3 3 3 3 3 3 3 4 3 4 4 4 4 4 4 | 4B3: Telematic and IT services to use same technology | 7A2: Implementation of UCS |
The phase numbers are also included in clause 4 above, for cross-reference purposes.
An attempt has been made to identify, for each item, the organization responsible,
related work, type of deliverable and a tentative time-table.
Already published results of European work are listed for information in clause 5.1.
| Taxonomy class | Title of document | Organization | Deliverable | Published | Action
| C/112 | European functional standards for character sets and their coding | CEN | R-IT-04 | 1990 | See Phase 1
| C/112 | Character repertoires and their coding | EWOS | TLG/PT 001 report | 1991 | none
| C/32 | Usage of coded character sets and repertoires in | EWOS | EWOS ETR | 1992 | none
| C/3311 | Character repertoire and coding for inter-working with telex services | CEN | ENV 41504 +AC | 1990, 1991 | Replace by EN 1922
| C/3312 | European character repertoires and their coding | CEN | ENV 41503 +AC | 1990, 1991 | Replace by EN 1923
| C/3312 | Graphic character repertoire and coding for line drawing | CEN | ENV 41505 | 1991 | Replace by EN 1923
| C/3312 | East European graphic character repertoires and their coding | CEN | ENV 41508 +AC | 1990, 1991 | Replace by EN 1923
| C/3332 | European ODA profiles | EWOS | ENV 41509, 41510, 41511 | - | Support UCS, see C/3332h
| C/3332 | Videotex presentation layer data syntax | ETSI | ETS 300072 | 1991 | Support UCS, see C/3332d
| C/3332 | International Videotex inter-working | ETSI | ETS 300105 | 1991 | Support UCS, see C/3332d
| C/3332 | Basic and recommended additional requirements for terminal equipment supporting
Teletex application | ETSI | ETS 300015 | 1995 | Support UCS, see C/3332g
| C/3332 | Specification of the Radio Data System (RDS) | CENELEC | EN 50067 | 1993 | Support UCS, see C/3332j
| C/3332 | European Radio Message System (ERMES); Part 2: Service aspects | ETSI | ETS 300133-2 | 1992 | Support UCS, see C/3332e-f
| C/3332 | Numeric keyboard for home electronic systems | CENELEC | EN 60948 | 1990 | a) Replace by EN ISO 9995, | see C/2111b. b) Support UCS in HBES, see C/3332k. |
| Item | Title | Org./Deliv. | Latest document | Formal vote starts | Expected publication
| / (no id) | Taxonomy of character set technology (TC-P4) | CEN CR | this report | 1995-12 | 1996-02
| L/11131 | Repertoires of letters used for writing the indigenous languages of Europe
(WG2-P11) | CEN CR | CEN/TC304 N379+B¡C5 | 1996-04 | 1996-06
| L/211 | Procedures for European registration of cultural elements (WG2-P2.1) | CEN ENV | prENV 12005 | 1995-07 | 1996-02
| C/112111 | European subsets of ISO/IEC 10646-1 (WG3-P10) | CEN ENV | ENV 1973 | 1995-06 | 1996-02
| C/3111 | Character repertoire and coding for inter-working with Telex Services (WG3-P8.3) | CEN EN | prEN 1922 | 1995-05 | 1996-05
| C/3112 | European repertoires and coding for Information processing (WG3-P6) | CEN EN | prEN 1923 | 1995-05 | 1996-05
| C/322 | International Standardized Profiles -- Character set code structure based on
ISO 2022 -- Part 1: FCS 111 -- 2022 Option 1 (TG-CS) | EWOS EN-ISP | prDISP 12070-01 | 1995-01 | 1995-12 | |
| Item | Title | Org./Deliv. | Latest document | Enquiry stage | Ready for formal vote
| L/111381a | Multilingual minimum subset ordering rules for Europe (WG1-P1.2) | CEN ENV | CEN/TC304 N436 | 1995-07 (TC) | 1996-12
| L/111381b | Multilingual extended subset ordering rules for Europe (WG1-P1.3) | CEN ENV | CEN/TC304 N436 | 1996-06 (TC) | 1997-06
| L/211 | Cultural elements (unregistered ones) (WG2-P2.2) | CEN CR | CEN/TC304 N449 | 1996-04 (TC) | 1998-04
| C/1121a | Transposition of ISO/IEC 10646-1 into EN.(WG3) | CEN EN-IS | ISO/IEC 10646:1993 +DCOR1 +DAM1-4 | 1995-09 (Public) | 1996-02
| C/112 | Guide on the use of character sets in Europe (Revision of R-IT-04) (TC-P3) | CEN CR | R-IT-04 | 1996-10 (TC) | 1997-04
| C/1212 | Description of problems and issues of transliteration and transcription within
Europe (WG4-P12) | CEN CR | CEN/TC304 N336 | 1996-04 (TC) | 1996-10
| C/1213a | European conversion and fallback rules -- Number 1: Conversion from European
subsets of UCS into ASCII (WG4-P9.2) | CEN EN | CEN/TC304 N446 | 1996-10 (Public) | 1997-10
| C/31311 | General model for character transformation (WG4-P9.1) | CEN ENV | CEN/TC304 N217 | 1996-10 (TC) | 1997-04
| C/323 | Use of the ISO/IEC 10646 code structure (TG-CS) | EWOS EN-ISP | - | 1996-06 (ED) | 1997-10 | |
| Item | Title | Org./Deliv. | Related work | Proposed enquiry sta. | Proposed ready for FV
| L/11113a | Guidelines and procedures for develop-ment of internationalized software
products (Glossasoft R-and-D results) | CEN ENVs | Glossasoft L/11113b | 1996-06 (TC) | 1996-12
| L/1311 | European default locale | CEN ENV | L/2111 | 1996-09 (TC) | 1997-06
| L/2111a | National standards on cultural conventions | NBs stds | L/1211, L/211 | 1995-1996 (national) | 1995-1997
| L/2111b | Guidelines on national specifications of cultural conventions | CEN CR-IS | JTC1/SC22 L/2111a | 1996-06 (TC) | 1996-12
| L/212 | International cultural registry | CEN EN-IS | JTC1/SC22 Replace ENV of L/211a | 1996-03 (Public) | 1997-03
| C/1121c | Maintenance of ISO/IEC 10646 | CEN EN-AMD /COR | ISO/IEC 10646 | on a stand-by basis | on a stand-by basis
| C/1121112 | Common 8-bit Braille character set | CEN EN-IS | ISO TC173 JTC1 | 1996-12 (TC) | 1997-06
| C/112132 | General symbol language representation | CEN ENV | TIDE JTC1 | 1996-12 (TC) | 1997-06
| C/113a | Character-glyph model for Europe | CEN ENV | C/113b (JTC1), C/1132 | 1996-12 (TC) | 1997-06
| C/1132 | Character-glyph correspondence for Europe | CEN ENV | C/113a+b | 1996-12 (TC) | 1997-06
| C/114 | Enhanced OCR-B standard for European use | CEN EN-IS | ISO 1073-2 SC17/ICAO | 1996-12 (Public) | 1997-12
| C/1213b | General European rules for fallback representation | CEN EN | C/1213a, C/1212, National work | 1996-10 (Public) | 1997-10
| C/2 | Input/output devices for disabled and elderly people (TC-HF) | ETSI ETSs | CEN, ISO, ETSI-workshop | various | various
| C/2111a | Standardized profile of UCS keyboard for Europe | CEN ENV | ISO/CD 14755, ISO/IEC 9995 C/1213 | 1996-09 (TC) | 1997-06
| C/2111b | Transposition of ISO/IEC 9995 into EN | CEN EN-IS | ETSI-HF CLC, EN 60948, CEN/TC122, CEN/TC224 | 1996-02 (Public) | 1996-09
| C/3131 | Guide on conversion between UCS coding forms | CEN CR-IS | ISO 9945-2b, WG20-APIs | 1996-06 (TC) | 1996-12
| C/331 | Guidelines for UCS in programming languages | CEN CR-IS | rev2 TR 10176 C/3311a+b | 1996-01 (CD/TC) | 1997-06
| C/3311b | Guidelines for the design of internation-alization | CEN CR-IS | = CD TR 10176 C/3311a | 1996-01 (CD/TC) | 1996-07
| C/332 | Support for Locale registry in POSIX operating systems | CEN EN-IS | rev. ISO 9945 L/31, L/1312 | 1997 | 1998
| C/3331 | Introduction of locales in ISO/IEC 9594 The Directory | CEN IS-AMD | ISO/IEC 9594 | 1996-01 (CD-AMD) | 1997-06
| C/3332a | Guidelines on providing multilingual functionality in ETSI standards (TC-HF) | ETSI ETR | all C/3332 PT and External experts needed | 1996-01
| 1996-06
| C/3332c | UCS in Digital Video Broadcasting -- (DVB) revised ETS 300468 (ETSI/EBU JTC) | ETSI ETS | EBU, CLC TC106, ENV 1973 | 1996 | 1997
| C/3332d | UCS in Videotex (TE1) | ETSI ETSs | old ETSs, ITU-T/SG8, ENV 1973 | 1996 | 1998
| C/3332e | UCS in Radio Paging (RES4) | ETSI ETS | GSM, ENV 1973 | 1996 | 1997
| C/3332f | UCS in text communication over GSM (TC-SGM) | ETSI ETS | RES4, ENV 1973 | 1996 | 1997
| C/3332g | UCS in MHS (EG-MHS) | EWOS ISs | ETSI/TE3, JTC1/SC18, CEN/TC304 | 1996 | 1998
| C/3332h | UCS in ODA (EG-SMMI) | EWOS ISs | ETSI/TE, JTC1/SC18, CEN/TC304 | 1996 | 1998
| C/3332i | UCS in SGML (EG-SMMI) | EWOS ISs | ETSI TE, JTC1/SC18, CEN/TC304 | 1996 | 1998
| C/3332k | UCS in HBES (TC 105) | CLC ENs | EN 60948, EN 50090, CEN/TC304 | 1996-12 (Public) | 1997-12 | |
| Item | Title | Org./Deliv. | Related work | Work can start | Could be ready for FV
| / (no id) | Taxonomy of character set technology (Revision) | CEN CR/M-IT | all | 1996/7 | 1998
| L/11111 | National translation of standard IT-terminology | NBs stds | JTC1/SC1 | various | various
| L/ 11112a | Terminological data exchange format (Transterm, Pointer, Genelex R-and-D results) | CEN, EN-IS | R-and-D projects, ISO TC37 (DIS 12200 and 12620) | 1996 | 1998
| L/11113b | Message interface with localizers | CEN EN-IS | Replaces ENV | 1996 | 1997
| L/11114 | Harmonized textual and lexical resources for automatic translation | CEN EN | Parole R-and-D results | 1996/7 | 1998
| L/111382 | Deterministic ordering of all UCS characters | CEN EN-IS | JTC1/SC22, WG20, Replace ENVs | 1995 (CD in Oct) | 1997/8
| L/1114 | Models of spoken language (Speechdat R-and-D results) | CEN ENV | Speechdat | 1997 | 1998
| L/1312 | Update POSIX to cover more cultural conventions | CEN EN-IS | rev ISO 9945, L/31 | 1996 | 1998
| L/132 | Formal specification techniques for cultural data (In addition to POSIX) | CEN EN-IS | JTC1/SC22 or /SC21 | 1995 | 1998
| L/31 | Update POSIX to include locale default rules | CEN EN-IS | rev ISO 9945, L/1312, C/332 | 1996 | 1998
| C/1111 | Short identifiers for characters | CEN EN-IS | JTC1/SC2 | 1996/7 | 1998
| C/1121b | Update UCS to include missing European characters | CEN EN-IS | ISO/IEC 10646 rev. EN-IS | 1995/6 | 1999
| C/112211 | Minimum set of control functions for Europe | CEN ENV | May be foll. by EN-ISP (JTC1) | 1995 | 1998
| C/113b | Global Character-Glyph model | CEN EN-IS | JTC1 | C/113a repl. ENV 1996/7 | 1998/9
| C/311 | Bar coding of European characters (TC225) | CEN EN | prEN 1923, ENV 1973 | 1996 | 1998
| C/313 | Tools and transformation tables | CEN CR/ENV | all C/313 | 1996 | 1997
| C/3311a | Support for UCS in programming languages | CEN ISs | JTC1/SC22 groups | 1995 | various
| C/3312 | Language independent API specification for internationalization and UCS | CEN CR-IS | JTC1/SC22, WG20 | 1995 | 1997/8
| C/3332j | UCS in RDS (TC107) | CLC EN | prEN 1923, ENV 1973 | 1996/7 | 1997/8
| C/3332l | UCS in IC-cards (TC224) | CEN EN | prEN 1923, ENV 1973 | 1996 | 1998
| C/3332m | UCS in Traffic Telematics (TC278) | CEN EN | prEN 1923, ENV 1973 | 1996 | 1998
| C/3332n | UCS in Medical Informatics (TC251) | CEN EN | EWOS, CLC, TC304-stds | 1996 | 1997/8
| C/3332o | UCS in Technical drawings and documentation | CEN EN-ISs | JTC1/SC24, IEC+ISO TCs, ENV 1973 | 1996 | various
| C/3332p | UCS in Library Informatics (ISO TC46) | CEN EN-ISs | EWOS EG-LIB ISO TC171 ENV 1973 prENV 12005 | 1996 | various | |
Related: all.
Deliverable: CR/M-IT-. Plan: start 1996/7, FV 1998.
L/11113a
Guidelines and procedures for development of internationalized software products. Phase: 3
Description: CEN/TC304 will take an immediate look at the Glossasoft deliverables
to see how they can be develops into European standards.
Related: Glossasoft R-and-D results, L/11113b.
Deliverable: ENV. Plan: TC 1996-06, FV 1996-12.
L/11114
Harmonized textual and lexical resources and tools for automatic translation. Phase: 4.
Description: Process proposals for European standards coming from Parole.
Related: Parole.
Deliverable: EN-IS. Plan: start 1996/7, FV 1998.
L/1114
Models of spoken language. Phase: 4.
Description: Develop a proposal expected from SPEECHDAT into a European standard.
Difficult item.
Related: Speechdat R-and-D results.
Deliverable: ENV. Plan: start 1997, FV 1998.
L/1311
European default locale. Phase: 3.
Description: The purpose of this work is to document those common European cultural
conventions that exist, in the form of a locale, for registration under the registration
standard on cultural conventions from TC304/WG2. The work is expected to cover at
least European ordering rules and may also cover date format, transliteration and
other conventions as found appropriate by the project.
Related: L/2111, making this a high-priority item.
Deliverable: ENV. Plan: TE 1996-09, FV 1997-06.
C/112132
General symbol language representation. Phase: 3
Related: TIDE, JTC1.
Deliverable: ENV. Plan: TE 1996-12, FV 1997-06.
C/112211
Minimum set of control functions for Europe. Phase: 4
Description: It is proposed that an ENV be developed which defines a model for the
USE of control functions, identifies a minimum set of control functions (BASIC) and
identifies a full set of control functions for text handling (FULL TEXT). Consideration should be given to the possibility of progressing this specification
outside Europe for adoption as an ISP since the document would be a profile of ISO/IEC
6424 and ISO/IEC 10538 and would complement the two ISPs being developed by EWOS.
Related: EWOS groups, SC2, SGFS, SC18, EPHOS Topic B, ECMA.
Deliverable: ENV (may be followed by EN-ISP). Plan: start 1996, FV 1998.
C/113a
Character-glyph model for Europe. Phase: 3
Deliverable: ENV. Plan: TE 1996-12. FV 1997-06.
C/1132
Character/Glyph correspondence for Europe. Phase: 3
Related: C/113a+b.
Deliverable: ENV. Plan: TE 1996-12, FV 1997-06.
C/1213b
General European rules for fallback representation. Phase: 3
Related: C/1213a, C/1212, national work foreseen.
Deliverable: EN. Plan: PE 1996-10, FV 1997-10.
C/2111a
Standardized profile of UCS keyboard for Europe. Phase: 3
Description: A technical study to see if the combination method needs national adaptations,
e.g. for the contents of the system file providing the mapping between key combinations
and target character.
Related: CD 14755, ISO 9995, C/1213.
Deliverable: ENV. Plan: TE 1996-09, FV 1997-06.
C/313
Tools and transformation tables. Phase: 4
Related: All C/313.
Deliverable: CR/ENV. Plan: start 1996, FV 1997.
Related: prEN 1923 and ENV 1973.
Deliverable EN. Plan: start 1996, FV 1998.
Related: EWOS-EG-MED, CENELEC TC62, prEN 1923, ENV 1973, prENV 12005, L/11113.
Deliverable: ENs/ENVs. Plan: start 1996, FV 1997/8.
Related: ISO 2382 series.
Deliverable: national standards. Plan: various (not urgent).
L/2111
National standards on cultural conventions. Phase: 3
Description: Develop national standards on cultural conventions. Work to be performed
by national bodies in co-operation with CEN/TC304.
Related: L/1211, L/212.
Deliverable: national standards. Plan: various (urgent).
Related: SC24, IEC+ISO TCs, ISO/IEC 10646, ENV 1973.
Deliverable: EN-ISs. Plan: start 1996, FV various.
L/11112a Terminological data exchange format. Phase: 4.
Description: Develop Terminological exchange format (eventually data base model) in
connection with the international TIF standardization in ISO/TC37 (ISO/DIS 12200,
ISO/DIS 12620).
Related: Transterm R-and-D results. ISO DIS 12200 and 12620.
Deliverable: EN-IS. Plan: start 1996, FV 1998.
C/3332p UCS in Library Informatics. Phase: 4
Related: EWOS-EG-LIB, ISO TC171, ENV 1973, prENV 12005.
Deliverable: EN-ISs. Plan: start 1996, FV various.
C/1121112 Common 8-bit Braille character set. Phase: 3
Related: ISO TC173, JTC1.
Deliverable: EN-IS. Plan: TE 1996-12, FV 1997-06.
Related: prEN 1923 and ENV 1973.
Deliverables EN-IS. Plan: start 1996, FV 1998.
C/1111 Short identifiers for characters. Phase: 4
Description: Develop a character identifier scheme using short identifiers.
Related: --.
Deliverable: EN-IS. Plan: start 1996/7, FV 1998.
C/1121b Update 10646 to include missing European characters. Phase: 4
Description: Revise 10646 to include the missing European characters, preferably in
BMP.
Related: C/1121 a+c.
Deliverable: revized EN-ISO/IEC 10646. Plan: start 1995/6, FV 1999.
C/1121c Maintenance of ISO/IEC 10646. Phase: 3.
Related: ISO/IEC 10646.
Deliverable: EN-AMD/COR. Plan: on a stand-by basis.
C/113b Global character-glyph mode. Phase: 4
Related: C/113a (replaces ENV), C/1132.
Deliverable: EN-IS. Plan: start 1995, FV 1998.
C/114 Enhanced OCR-B standard for European use. Phase: 4.
Description: If no revision is taking place in ISO then TC304 should consider undertaking
the work because a number of important application standards are dependent upon OCR-B.
Related: ISO 1073-2, SC17/ICAO
Deliverable: CEN-EN-IS. Plan: TC 1996-12, FV 1997-12.
Related: prEN 1923 and ENV 1973.
Deliverables EN-IS. Plan: start 1996, FV 1998.
Related: C/2111a, ETSI HF, CENELEC EN 60948, CEN TC122, CEN TC224.
Deliverable: Multi-part EN. Plan: PE 1996-02 FV 1996-09
C/3331 Introduction of locales in ISO/IEC 9594 The Directory. Phase: 3
Description: Develop an amendment to ISO/IEC 9594 to include full support for all
Locale items specified in the European/International registry of cultural elements.
Work to be performed by ISO/IEC JTC1 SC21, input from CEN. Pilot projects are recommended.
Related: C/332.
Deliverable: AMD. to ISO/IEC 9594 (not EN). Plan: CD 1996-01, FV 1997-06.
Description: Develop an international standard, based on the ENV coming from the Glossasoft
work.
Related: ENV.
Deliverable: EN-IS (to replace ENV). Plan: start 1996, FV 1997
L/111382 Deterministic ordering of all UCS characters. Phase: 4.
Related: CEN work (L/111381).
Deliverable: EN-IS (replace ENV). Plan: CD/TC 1995-10, FV 1997/8
L/1312 Update POSIX to cover more cultural conventions. Phase: 4.
Related: L/31, C/332.
Deliverable: Revized EN-ISO/IEC 9945. Plan: start 1996, FV 1998.
L/132 Formal specification techniques for cultural data (in addition to POSIX).
Phase: 4
Related: SC21, ISO/IEC 9945-update.
Deliverable: EN-IS. Plan: start 1995, FV 1998.
L/2111b Guidelines on national specifications of cultural conventions. Phase:
3
Description: Develop European guidelines that can serve as input to the international
work item.
Related: L/2111a.
Deliverable: CR-IS. Plan: TE 1996-06, FV 1996-12.
L/212 International cultural registry. Phase: 3
Related: SC22 work, L/211a (replace ENV)
Deliverable: EN-IS. Plan: PE 1996-03, FV 1997-03.
L/31 Update POSIX to include locale default rules. Phase: 4
Description: The internationalization model and APIs need to be modified to accommodate
this need. New, but small item for WG15.
Related: L/1312, C/332.
Deliverable: Revized EN-ISO/IEC 9945. Plan: start 1996, FV 1998
C/3131 Guide on conversion between UCS coding forms. Phase: 3
Description: A guide will be developed for implementers of conversion functions in
operating systems (such as POSIX iconv). This guide could be input to the WG20 work
on APIs for internationalization.
Related: 9995-2b, WG20-APIs.
Deliverable: CR-IS. Plan: TE 1996-06, FV 1996-12.
C/331 Guidelines for UCS in programming languages. Phase: 3.
Related: C/3311a+b.
Deliverable: CR TR 10176 (3rd edition). Plan: CD/TC 1996-10, FV 1997-06.
C/3311a Support for UCS in programming languages. Phase: 4.
Related: SC22 groups.
Deliverable: ISs (not to be transposed). Plan: start 1995, FV various.
C/3311b Guidelines for the design of internationalization. Phase: 3.
Related: C/331, C/3311a.
Deliverable: CD TR 10176 (2nd edition). Plan: CD/TR 1996-01, FV 1996-07.
C/3312 Language independent API specification for internationalization and UCS. Phase: 4.
Related: C/331, C/3311a-b.
Deliverable: EN-IS. Plan: start 1995, FV 1997/8.
C/332 Support for Locale registry in POSIX operating systems. Phase: 3.
Related: SC22/WG15.
Deliverable: EN-ISO/IEC 9945 rev. 1. Plan: TC 1997, FV 1998.
C/3332g UCS in MHS. Phase: 3
Description: Update MHS standards to include support for UCS, Locales and internationalization.
EG-MHS to liaise with ETSI and JTC1. CEN can provide input if needed.
Related: ETSI/TE3, JTC1/SC18, CEN/TC304.
Deliverables: ISO standards (not to be transposed). Plan: CD 1996, FV 1998.
C/3332h UCS in ODA. Phase: 3
Description: Update ODA standards to include support for UCS, Locales and internationalization.
EG-SMMI to liaise with ETSI and JTC1. CEN can provide input if needed.
Related: ETSI/TE, JTC1/SC18, CEN/TC304.
Deliverables: ISO standards (not to be transposed). Plan: CD 1996, FV 1998.
C/3332i UCS in SGML. Phase: 3
Related: ETSI TE, JTC1/SC18, CEN/TC304
Deliverable: ISO standards (not to be transposed). Plan: CD 1996, FV 1998
C/2 Input/output devices for disabled and elderly people. Phase: 3
Description: A work programme is needed to study and identify the possible input/output
devices which give a suitable match to a range of disabilities and their combinations
and define suitable interface protocols for connection and signalling in the IT and telecommunications environment. One of the items is a standard method for the special text telephony used by deaf
and hearing and speech impaired persons to be developed and standardized. The national
7-bit coded character set used today will be replaced by (preferably) ISO/IEC 10646.
A small set of control functions will be developed to control real time text conversations.
The system will be able to connect to common electronic mail systems. Work to be performed by ETSI TC-HF and TC-TE.
Related: Inputs from CEN and co-operation with TIDE and similar programs, in particular
ISO TC173, CEN TC293 and the ETSI/EU workshop on disabilities planned in 1996.
Deliverables: Multiple ETS/ETR. Plan: various.
C/3332a Guidelines on providing multilingual functionality in ETSI standards. Phase: 3
Description: A study will analyse Telematic services with respect to how UCS can be implemented in the future standards for these services. It is proposed that the study be carried out by ETSI/HF and the results be made available to all ETSI groups in the form of guidelines for providing multilingual functionality in applications. Work for TC-HF -- Project Team including external experts.
Related: All C/3332.
Deliverable: ETR. Plan: TC 1996-01, FV 1996-06.
C/3332c UCS in Digital Video Broadcasting. Phase: 3
Related: EBU, CLC TC106, ENV 1973.
Deliverable: rev. ETS 300468. Plan: TC 1996, FV 1997.
C/3332d UCS in Videotex. Phase: 3
Related: ENV 1973.
Deliverable: revized ETSs. Plan: TC 1996, FV 1998
C/3332e UCS in radio paging. Phase: 3
Related: GSM, ENV 1973.
Deliverable: ETS (one or more). Plan: TC 1996, FV 1997
C/3332f UCS in text communication over GSM. Phase 3.
Related: RES4, ENV 1973.
Deliverable: ETS (one or more). Plan: TC 1996, FV 1997
C/3332g UCS in MHS see clause 7.
C/3332h UCS in ODA see clause 7.
C/3332i UCS in SGML
see clause 7.
C/3332c UCS in Digital Video Broadcasting see clause 8.
C/3332j UCS in RDS. Phase: 4
Related: prEN 1923 ENV 1973.
Deliverable: EN. Plan: start 1996/7, FV 1998
C/3332k UCS in HBES. Phase: 3
Related: EN 60948, CEN/TC304
Deliverable: revised EN 50090-1, -2 and -3. Plan: PE 1996-12. FV 1997-12
Various published articles on Internationalization of IT.
Additional references are in annexes C-F
STANDARDIZATION MANDATE ADDRESSED TO CEN/CENELEC/ETSI IN THE AREA OF CHARACTER TECHNOLOGY
PURPOSE
The standardization organizations CEN, CENELEC and ETSI should define a coherent work
programme for character repertoires an coding, including a Taxonomy for Character
Set Technology.
HISTORY
The last years have seen a major technological evolution, accompanied by an equally
important cost reduction, which all together have made information processing very
wide spread, and no more the reserved domain of highly qualified specialists.
In parallel, the evolution of the communication concepts, materialized by the OSI
standards, has created a new environment which does not constrain a processing system
by limiting its communication capabilities to a closed set of proprietary protocols.
Therefore, it is obvious that the definition and coding of the character repertoires have to be revized and a policy must be defined in accordance with the new context and the new requirements.
It is also obvious that the current systems must be adapted to the new situation.
Consequently, character repertoires solutions are required for the new environment,
together with a clear migration strategy for existing equipment.
The European standardization organizations have up to now published several standardization documents concerning sets and coding e.g.
a) European standards:
a) Define an European policy and strategy with respect to Character Repertoires and
their encodings.
b) To align the existing and ongoing standardization activities with this policy.
ORDER
The Commission invites CEN in co-operation with CENELEC, ETSI and EWOS to define an European work programme for Character Repertoires and coding including a taxonomy for character set technology.
The work programme should:
When establishing user requirements due note should be taken of existing material which may have been developed within national activities such as Statskontoret Teknisk Norm Nr. 34.1.
b) reflect the commonalty of user requirements and define all required standardization activities in order to realize the user functionality as defined in (a). It will make a clear separation of standardization activities which reflect user requirements and those required for realization of user requirements.
The work programme should also include:
The information in F.9 is taken from ENV 1973 and lists only those languages covered
by the Minimum European Subset of UCS.